
Hashes and blockchains. This article focuses on describing what hashing algorithms are, how they work and what are the characteristics that made them widely used to ensure the integrity of data and communication in the digital world. It also provides a high level explanation of how hashing is utilized on the blockchain architecture and how it is considered the glue that give blockchains their capabilities to maintain integrity.
Whether you know it or not, hashes are widely used in the digital world, they are the silent “heroes” ensuring the integrity of our data. In cryptography (the science of encrypting stuff), hash functions are mostly used to assure the integrity of data stored, in transit or in execution.
The analogy
You could think of a hash as a fingerprint; for instance, when you setup your phone to use fingerprint authentication, you are basically reducing your identity to ones and zeros, anytime you put your finger in, the sensor reads your fingerprint and compares it to whatever was previously stored, if they match the user is authenticated, otherwise it is not.
Hashes are the same, they are the digital fingerprint of data, meaning that they can take any size of data and reduce it to a fixed-length value that represents the data itself. As we will see below, if you make any change to the initial data, the calculated hash (or digital fingerprint) will be completely different.
Hashes are the digital fingerprint of data, they are foundational for digital signature.
What is a hash algorithm?
Also known as digests, a hash algorithm takes variable-length input and produces a fixed-length value (or hash), which represents the digital fingerprint of the data provided as input.
They are a one-way algorithms, meaning that, with the data at hand you can calculate the hash of said data. However, if you only have the hash, you should not be able to obtain, within a reasonable amount of time, the original data from which the hash was calculated (this is true if hashing is done properly).
Hashing algorithms operates at the bit level, which means that whether you change the whole data or just just 1 bit of that data, you will still get a completely different hash value.
What else?
Another interesting characteristic of hashes is that they produce a fixed-length output value from a variable-length input. Let’s say we provide a hash function with an input of a 1Kb file and the functions generates a 256 bit hash value, if we provide the same function with a 100Mb file, the function will still produce an output of 256 bits, a completely different output, but still the same length as the one obtained from the 1Kb file.
Hashing algorithms should also be quick, deterministic, collision resistant and pre-image attack resistant. These algorithms are, in fact, very quick to compute, and that (along with the other stuff discussed here) make hashing algorithms widely used to ensure the integrity of communications carried out over a secured channel, i.e.: TLS.
Hashing algorithms should also be quick, deterministic, collision resistant and pre-image attack resistant.
They should be deterministic in the sense that the same input data should always produce the same hash output. Collision resistant means that it is computationally infeasible to find two different inputs that produce the same hash value. And finally they should be resistant to the pre-image attack which, in short, means that hashing algorithms should make it also computationally infeasible to find the input that hashes to the hash value.
Hashing is not encrypting
Since hashing is a cryptographic algorithm it is, sometimes, misunderstood as an encryption algorithm, but it couldn’t be farther from that. Unlike other cryptographic functions, there is no key involved in hashing, you don’t need a key to hash data. Hashing takes a digital fingerprint of data, it does not, in anyway encrypts it.
Hashes and blockchains
As we saw before, hashes have characteristics specifically designed to enforce data integrity, they are used to digitally sign data. They are also the backbone for maintaining integrity of each of the blocks (and the chain itself) within the blockchain architecture.
To reduce it in some way, a blockchain is exactly that, a bunch of blocks of data that are chained one after the other, similar to a linked list in programming. A block can be thought of as lists transactions, however, from a security point of view, the interesting part comes in how the chaining is done.
In blockchain, the chaining part is achieved by the use of hashing algorithms.
You see, each block on the blockchain has a “pointer” to the previous block in the chain, except for the genesis block, which is the first block of the chain. The “pointer” itself is no more than a field in the block that contains the computed hash value of the previous block.
The image below is taken from the blockchain whitepaper and it gives a high level idea of how the chain is constructed (even though it is taken from Section 3 Timestamp Server).
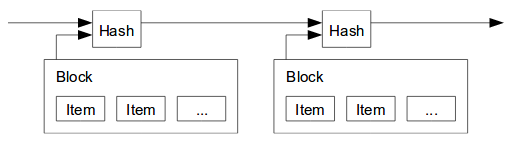
In fact, each of the blocks has, built into itself, the digital signature of the previous block in the form of a hash. This means that, when a block of transactions has been added to the blockchain, it cannot be changed, it is an undeniable record that the list of transactions took place.
Merkle tree hashes
Another interesting usage of hashes within blockchain, is in the form of a merkle tree, which is no more than a hash tree. In a hash tree, leafs represent hashes of data and non-leaves are a hashes of the child nodes (see image below, also taken from here).
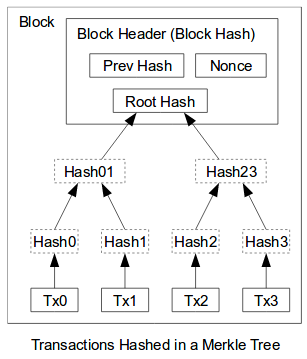
A hash tree is a very efficient data structure. It provides easy data verification and efficient disk space usage
This data structure provides blockchains with two amazing capabilities:
Easy data verification
We are dealing with distributed systems after all, been able to quickly verify data across the decentralized network is essential. Merkle trees are an easy way to achieve that.
Imagine you have some data and you want to verify it’s integrity, that is to say that the data is the same everywhere else in the network. Instead of transmitting the whole data across the network for comparison, we only compute the hash of the data, this value is then compared with the ones on the merkle tree to ensure that the data has not been tampered with.
Disk space efficiency
Merkle trees are also very efficient in it’s usage of disk space. This is vital for peer-to-peer networks, in which every node of the network has to keep a representation (namely the merkle tree) of entire blockchain.
Conclusions
Hashes are widely used in security, mainly to maintain data integrity. They also play a vital role in the blockchain technology, they help in maintaining the integrity of blocks and the blockchain itself. Hashes are also used in merkle trees to easily verify data and because of it’s efficient use of disk space.
Resources
[1] https://www.movable-type.co.uk/scripts/sha256.html
[2] https://www.sans.edu/cyber-research/security-laboratory/article/hash-functions
[3] https://resources.infosecinstitute.com/hashes-in-computer-security/
What are Smart Contracts? [The true power of blockchain] – Part 1
Recent Comments